xv6 のブートローダーを読む
xv6 では、それ自身でもブートする機能があります。 xv6のブート機能によって、BIOS からカーネルのエントリポイントへと処理が移って行く様を観察します。
* 勉強中の身なのでたくさんの間違いがあると思います。お気づきの場合には twitter などで指摘してください。
なぜブートローダーか
世に溢れる unix 系の本では、そのほとんどの話が起動後のカーネルのお話です。これは Kernel を理解するにはとても大事なことだとは思います。 しかし、これから低レイヤーに入門しようと思う僕のような初心者にとっては、残念ながらそれらの書籍では、逆に情報が足りなさすぎて途方にくれてしまうことがあります。
この物足りなさは、コンピューター(ハード)とカーネルとの接続点が不明なまま話がすすんでしまうことに起因していると思います。 このような状況は、カーネルを探検する前に、険しい崖、鬱蒼とした森に目の前を遮られているような状況です。当然、目隠ししたままでは、カーネルの探検をしようがありません。
ブートプロセスの初期段階を理解するという工程、もしくは、ブートローダーを自作するという工程は、このハードとソフトに横たわる隔たりを埋め、目隠しを取り払ってくれるものだと思います。
一見遠回りのように見えますが、むき出しのカーネルにふれ、実際にカーネルを探検して行くためには本来不可欠なプロセスだと考えます。
ここでは、そんなブートローダーのソースリストを xv6 を題材に読んでみます。
概要と実際に読むソースリスト
xv6 のブートローダーには ELF 実行形式を理解してロードする機能があります。 具体的には、xv6のブートセクタは、現在ロードし、実行しようとしているカーネルイメージがELF実行形式かどうかをしっかりと確かめ、セグメントを ELF の形式でロードし、ELF の エントリーポイントから実行を開始します。この点でも、xv6 のブートローダーは学習に適しているのではないかと思います。
また、xv6 は小さくて洗練されています。今回使用するソースリストはとても少ないので、とくに心配はいらないかと思います。
xv6 の初期ブートプロセスを探検しよう
基本のキ 探検の仕方
ここでは、ソースを読むという作業が多くなるのですが、カーネルのソースリストを読むというときにどのように対応されているでしょうか。
ファイル名から見るべきソースが検討ついたとしても、grepで単語検索で一発だとしても、最初から場当たり的に探検して行くのは避けたほうがいいと僕は思います。こういった探検の仕方は、体系的な理解の妨げになりかねないとおもいます。僕は、まず経験的に Makefile から確認するようにしています。
なぜかというと、Makefile を見れば、なんのヘッダー/ソースリスト、オブジェクトファイルが必要で、なんのリンカースクリプトを使っていて、どんなものができるのか一目瞭然だからです。 この情報は、カーネルを読む際のソースコードリーディングに指向性を与えてくて理解の助けになると思います(Linux を読むときはまず Makefile の解読がかなり大変なのですが、こちらも枝葉を徹底的にこそぎ落としてエッセンスを掴んでいけばそこまで難しいものではないように思えます)。
ということで、僕としてはソースを見るときにはまず Makefile を確認することをオススメさせていただきます。 *完全に我流ですので もし他にもっといい方法があったら教えてください。
それでは、処理の流れを外観した後、実際に Makefile の中身を見ていきましょう。
処理の流れ(一言で)
- ブートセクタ512バイトのプログラムをロード、セグメント0:オフセット0x7C00よりリアルモードで実行開始
- セグメントレジスタ(DS,ES,SS)を0に設定
- A20ラインを有効化しアドレスバスを32bit化した上で、プロテクトモードに移行
- カーネルイメージをELFプログラムヘッダに従って、ロードした上で、処理がカーネルに移る
Makefile の中身
さっそくですが、Makefileを抜粋して見ました。今回の目的には関係のなさそうな部分は省略しています。
xv6.img: bootblock kernel
dd if=/dev/zero of=xv6.img count=10000
dd if=bootblock of=xv6.img conv=notrunc
dd if=kernel of=xv6.img seek=1 conv=notrunc
bootblock: bootasm.S bootmain.c
$(CC) $(CFLAGS) -fno-pic -O -nostdinc -I. -c bootmain.c
$(CC) $(CFLAGS) -fno-pic -nostdinc -I. -c bootasm.S
$(LD) $(LDFLAGS) -N -e start -Ttext 0x7C00 -o bootblock.o bootasm.o bootmain.o
$(OBJDUMP) -S bootblock.o > bootblock.asm
$(OBJCOPY) -S -O binary -j .text bootblock.o bootblock
./sign.pl bootblock
kernel: $(OBJS) entry.o entryother initcode kernel.ld
$(LD) $(LDFLAGS) -T kernel.ld -o kernel entry.o $(OBJS) -b binary initcode entryother
$(OBJDUMP) -S kernel > kernel.asm
$(OBJDUMP) -t kernel | sed '1,/SYMBOL TABLE/d; s/ .* / /; /^$$/d' > kernel.sym
bochs : fs.img xv6.img
if [ ! -e .bochsrc ]; then ln -s dot-bochsrc .bochsrc; fi
bochs -q
突然ですが、上記のリストのうち、一番下の行の bochs のブロックに注目してください。 こういうところも僕のような初心者には大事な情報です。この1行から、xv6のコアイメージは xv6.img であることが容易にわかりますね。まず動くもの、ターゲットを見つけるようにするのはいい手段なのではないかと思います。
さて、次はこのxv6.img がどのようにして作成されているのか見てみましょう。Makefileをもう一度みてみると次のブロックが見つかりますね。bootblock kernelという二つのファイルを、それぞれ dd で xv6.img ファイルに書き込んで作っている状況に気がつきます。
xv6.img: bootblock kernel
dd if=/dev/zero of=xv6.img count=10000
dd if=bootblock of=xv6.img conv=notrunc
dd if=kernel of=xv6.img seek=1 conv=notrunc
もう少し詳細に見ると、/dev/zero でまずイメーファイルをゼロクリアした後に、先に bootblock を書き込んで、その後、きっちり 512B 分後方に kernel ファイルを書き込んでいる様子がわかります dd if=kernel of=xv6.img seek=1 。
名前からも明らかだと思うのですが、ここから色々予想することができます。 例えばいかのような感じではないでしょうか?
【疑問1】 「bootblockがブートセクタにちがいない。kernel がすぐその後ろに書き込まれているので、xv6 ではブートセクターに格納できるだけのコードサイズでカーネルのロードを行う様子」 【疑問2】 「ブートセクターの目印は一つはブートシグネチャで、その書き込み方法には特徴がでる。リンカースクリプト/アセンブリ/Cソース内で定義しているのか、それとも後から書き込んでるのか」
ここでブートセクタについて知らない方のために簡単に解説しておきます。
ブートセクタ
PC/AT互換機に電源が入ると、まず ROM BIOS が実行され、システムの初期化を行った後にブートデバイスの先頭セクタ512バイトがメモリ上の所定の位置に読み込まれます。この先頭 512B のことをブートセクタと言います。そして、ブートセクタのロードが完了すると、CPUはその先頭アドレスにジャンプして実行を開始します。
なお、ブートセクタの512バイトの範囲内であれば自由にブートプログラムを記述することが可能です。xv6 はこの範囲で、もろもろの設定からカーネルのロードと実行までを行ってしまいます。
先ほど、ブートセクタはメモリの所定の位置にロードされると言いましたが、具体的には、ブートセクタはセグメント0:オフセット0x7C00番地からの512バイトに読み込まれます。そして、CPUは同アドレスにジャンプすることになります。ここは大事なところなので覚えておいて損はないでしょう。なんでこのようになっているのかはいまいちわかっていないのですが、セグメント0全体から見ると、ブートプログラムは前後の 32KB を分断するように中央に位置していることがわかります(ここで言っている意味がわからない方は下記のリアルモードとは?を参照してください)。
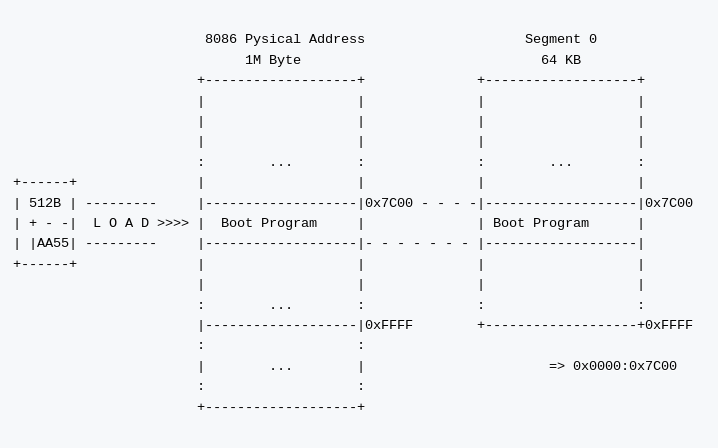
補足として、一つ注意点があります。
ブートコードが読み込まれた ブートセクタ内オフセット 0x1FE 番地、すなわちセクタ内の最終2バイトに 0xAA55 というデータが配置されていない場合には、正しいブートディスクとは認識されません。このため、0xAA55 のことを「ブートシグネチャ」と呼びます(BIOSによってはブートシグネチャが存在しなくても起動できる場合があります。また CMOS 設定でこの挙動を制御できる BIOS も存在しますので、ご利用になる BIOS を調べておくのもいいでしょう)。
さて、ここで、実行されるCPUのモードは基本的にリアルモード(8086)です。リアルモードis何?というリアルモードを知らない方のためにも、リアルモードについても簡単に触れておきましょう。
リアルモードとは? 8086 におけるリニアアドレス
リアルモードは20ビットのアドレス空間で動作する CPU の実行モードです。そして、ほとんどのサーバーでは、最初にかならずこの原始8086リアルモードを通過し、周辺機器を初期化したうえで、32bitプロテクトモードへ移行し xv6 や Linux を起動することになるわけです。
さて、セクション冒頭で述べたように、8086 の全アドレス空間は 20 ビットすなわち 1 Mバイトなのですが、8086 のレジスタは 16 bit 分しかありません。つまり、アドレス空間 20 bit に対し、アドレッシング指定可能なオフセットアドレスは 4 ビット少ない16ビット分の情報しか保持できないのです。これは仕様なのですが、単純に考えると 64 Kバイトまでの範囲しかアクセスできないことになります。到底 1MB (20bit)には届きません。これはおかしいぞと考えます。実は 8 ビットCPU時代のしがらみを引きずった結果なのですが、、、いまだにこの呪縛にしばられている様子はなんだか面白いなぁと思います。
【疑問3】 「メモリは 1M バイトほしいが、CPU は64Kバイトの範囲しかアクセスできない。どうすればいい?」
そこで、このジレンマを解決するために、インテルの開発者は 16bit のセグメントレジスタを導入しました。 簡単に解説すると、このセグメントレジスタはそれぞれのセグメントの「ベースアドレス」を設定するものです。 80286以上のCPUではセグメント情報を格納するセグメントディスクプリタ中のベースアドレスがこの機能に相当しますが、こちらは32ビット長でした。ところが、8086の4種類のセグメントレジスタはいずれも16ビット長しかありません。どのように 20bit を表現するのでしょうか。
16 ビットで20ビットを表現するために、8086は 内部でセグメントレジスタの値を単純に4ビット左シフトします(つまり16倍するわけなのです)。これによって、20 bit 目が現れてくれます。単純ですね。 ちなみに、このためにセグメントの開始アドレスは16の倍数でなければならないという制限も発生します(16bytes alignment)。
このようにして、リアルモードでの最終アドレスは 16ビットセグメントレジスタ値を16倍して得られる20ビットのベースアドレス、と、16ビットのオフセットアドレスを合計したものになります。これをリニアアドレスといい、この 64KB 分のエリアをセグメントといったりします。
例:

リアルモードでは、このリニアアドレスと 物理アドレスは同一ですが、ページング機構が有効になったプロテクトモードではメモリマッピングにより、必ずしも同じ値になるとは限りません。また、プロテクトモードでセグメントレジスタに格納される値はリアルモードのような絶対値ではなくて、セグメントディスクプリタのオフセットアドレス(セレクタ)になります。詳細はソースリストを読むことをを通して明かしていきたい、と言いたいところですが、くわしく知りたい方はなんらかの参考書をあたってください。おすすめは「はじめて読む 486 」です。
さて、ここでの関心はブートローダーでした、横道にそれすぎましたが、先程の疑問 1,2 を元に bootblock をみていきます。
bootblock の構成とシグネチャについて
bootblock の Makefile 箇所は以下のようになっています。
bootblock: bootasm.S bootmain.c
$(CC) $(CFLAGS) -fno-pic -O -nostdinc -I. -c bootmain.c
$(CC) $(CFLAGS) -fno-pic -nostdinc -I. -c bootasm.S
$(LD) $(LDFLAGS) -N -e start -Ttext 0x7C00 -o bootblock.o bootasm.o bootmain.o
$(OBJDUMP) -S bootblock.o > bootblock.asm
$(OBJCOPY) -S -O binary -j .text bootblock.o bootblock
./sign.pl bootblock
どうやらあたりのようでね。
リンカースクリプトはないのですが、 $(LD) から始まる行を見てください。
エントリポイントが0x7C00から始まる start シンボル(重要!)として設定されているのがわかります -e start -Ttext 0x7C00 。
先に解説したように BIOS からメモリに読み込まれたブートセクタは 0x0000:0x7C00 に展開されており、ここから実行を開始されるのでした。つまり、この1行からもこのブロックで作成される bootblock がブートセクタの本体であると確定できます。また、必要なソースのリストから xv6 ブートローダーは bootasm.S bootmain.c が大元であることがわかります。
そして気が早くはあるのですが、何やらこのターゲットの最後に変なperlスクリプトが見えます。 ./sign.pl bootblock です。 sign という名称はなんとも怪しいですね?ここから、もしやこれはブートシグネチャの設定をしているのではと勘ぐるわけです。単純なソースなので先に見てみましょうか。
#!/usr/bin/perl
open(SIG, $ARGV[0]) || die "open $ARGV[0]: $!";
$n = sysread(SIG, $buf, 1000);
if($n > 510){
print STDERR "boot block too large: $n bytes (max 510)\n";
exit 1;
}
print STDERR "boot block is $n bytes (max 510)\n";
$buf .= "\0" x (510-$n);
$buf .= "\x55\xAA";
open(SIG, ">$ARGV[0]") || die "open >$ARGV[0]: $!";
print SIG $buf;
close SIG;
なんとびっくり、512B 中の最後尾2バイトに、"\x55\xAA" という文字列を埋め込んでいるではありませんか!覚えていますね。これはブートセクタのブートシグネチャです。このシグネチャがないディスクからは起動できません。BIOS によって弾かれるのでした。
ということで、xv6.img は以下のようになっており、また、メモリに読み込まれて実行がスタートしていく様が容易に想像できます(単なる再掲です)。
次に、実行されるコードを具体的にみて、何をしているのかチェックしていきましょう。
bootblock の実装を実際に見る
bootblock のソースは bootasm.S とbootmain.c でした。
なお、gcc の引数指定より .S の方が先にリンクされるので、 bootasm.S のソースを見ていけばいいことになります。また、先の Makefile の内容から、ブートセクタの実行はエントリポイント 0x7C00 の start シンボルから始まるのでしたね。ということは、実態を追っていくためにもまず、bootblock のエントリポイントである start シンボルのありかを探せばいいということがわかります。bootasm.S の中身を見て見ましょう。
下記のソースを見てください。短いので全部コピーしてきました。コメントは煩雑になるので抜かしてます。
#include "asm.h"
#include "memlayout.h"
#include "mmu.h"
.code16 // Assemble for 16-bit mode
.globl start
start:
cli // BIOS enabled interrupts; disable
// Zero data segment registers DS, ES, and SS.
xorw %ax,%ax // Set %ax to zero
movw %ax,%ds // -> Data Segment
movw %ax,%es // -> Extra Segment
movw %ax,%ss // -> Stack Segment
seta20.1:
inb $0x64,%al // Wait for not busy
testb $0x2,%al
jnz seta20.1
movb $0xd1,%al // 0xd1 -> port 0x64
outb %al,$0x64
seta20.2:
inb $0x64,%al // Wait for not busy
testb $0x2,%al
jnz seta20.2
movb $0xdf,%al // 0xdf -> port 0x60
outb %al,$0x60
lgdt gdtdesc
movl %cr0, %eax
orl $CR0_PE, %eax
movl %eax, %cr0
ljmp $(SEG_KCODE<<3), $start32
.code32 // Tell assembler to generate 32-bit code now.
start32:
// Set up the protected-mode data segment registers
movw $(SEG_KDATA<<3), %ax // Our data segment selector
movw %ax, %ds // -> DS: Data Segment
movw %ax, %es // -> ES: Extra Segment
movw %ax, %ss // -> SS: Stack Segment
movw $0, %ax // Zero segments not ready for use
movw %ax, %fs // -> FS
movw %ax, %gs // -> GS
// Set up the stack pointer and call into C.
movl $start, %esp
call bootmain
movw $0x8a00, %ax // 0x8a00 -> port 0x8a00
movw %ax, %dx
outw %ax, %dx
movw $0x8ae0, %ax // 0x8ae0 -> port 0x8a00
outw %ax, %dx
spin:
jmp spin
// Bootstrap GDT
.p2align 2 // force 4 byte alignment
gdt:
SEG_NULLASM // null seg
SEG_ASM(STA_X|STA_R, 0x0, 0xffffffff) // code seg
SEG_ASM(STA_W, 0x0, 0xffffffff) // data seg
gdtdesc:
.word (gdtdesc - gdt - 1) // sizeof(gdt) - 1
.long gdt // address gdt
ソースを読み始める前に、最低限 gas の以下のルールは頭に入れて起きましょう。
さて、ここでのコードはどれも当たり前であまりおもしろみを感じませんが、余分なものが無いという点でシンプルで見やすいです。 順番に見ていきます。
.code16 // Assemble for 16-bit mode
.globl start
start:
cli // BIOS enabled interrupts; disable
// Zero data segment registers DS, ES, and SS.
xorw %ax,%ax // Set %ax to zero
movw %ax,%ds // -> Data Segment
movw %ax,%es // -> Extra Segment
movw %ax,%ss // -> Stack Segment
早速、bootmasm.Sに start ラベルがあるのを見つけましたね。
もはや答えはわかりましたが、各コードの意味も順番に吟味して起きましょう。
.code16 ディレクティブは 16 bit モードの開始であることを示しています。
つまりこのディレクティブ以降のコードは次に明示的に 32bit モードであることをアセンブラに指示するまで、16 bit リアルモードとしてアセンブルされます。
.globl start では start エントリアドレスを外部オブジェクトファイルが参照可能なようにグローバル宣言しています。gcc でエントリ指定していたのはこれですね。つまりここからいよいよ実行コードがはじまるわけなのです。
プログラム先頭では、 cli 命令でまず割り込みを無効化していますが、セグメントの値が途中で変わったりしたら怖いので無難な操作でしょう。
そのあとでは、DS, ES, SS セグメントをセグメント値 0 にそろえています。なぜかというと、BIOS にロードされたブートセクタはコードセグメント 0 ,オフセット 0x7C00 に位置しているからです。データセグメントなど実際に使うセグメントについてはプログラマの責任で意図した値に設定しておく必要があります。この操作は必須操作なので覚えておきましょう。
たとえば、DS レジスタはCPUが加工するデータのベースアドレスになります。セグメントのベースがそろっていないとデータへのアクセスが煩雑になるばかりか(アドレスの計算)、64KB 制限により、意図したデータにアクセスできないこともあります。注意しましょう。
なお、CS(Code Segment) レジスタは名前のとおり、CPUが実行するコードを読み込むために使われています。
さて、どうやら、xv6ではセグメント0まま処理を進めていくようですね。
横道にそれますが、64KBを見通しよくフルに活用したいブートローダーでは、よくここでセグメント間ジャンプを実行して、実行セグメントを 0x0000 から 0x07C00 に設定し直すことが多いように思います。先にも説明した通り、セグメント0のままだと、セグメント全体から見ると、ブートプログラムが前後の32Kバイトを分断するように、中央に位置していることになります。これでは、このブートプログラムはお邪魔虫状態でなんだかムズムズします。セグメントを 0 から 0x07C0 へ、ブートプログラムの開始オフセットアドレスを 0 に変更するようにすれば、セグメント 0x07C0 の全体の 64KB を見通しよく利用することができます。なので、個人的にはそのほうがわかりやすくていいとと思うのですが、xv6 は特にそのような変更をしていませんね。
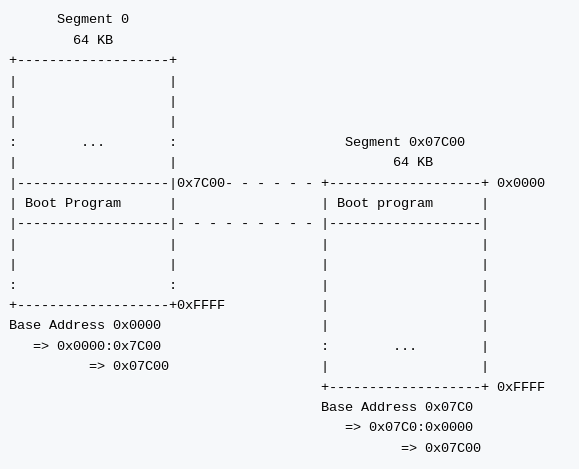
ちなみに変更自体はセグメント間ジャンプで簡単に行えます。
【疑問4】 僕だったら以下のようなコードに書き換えてしまうかもしれません。xv6 はなぜこのようにしないのでしょうか。
.code16 // Assemble for 16-bit mode
.globl start
start:
ljmp $0x07C0, $reentry // Do inter-segment jmp
reentry:
cli // BIOS enabled interrupts; disable
// Zero data segment registers DS, ES, and SS.
movw $0x07C0, %ax // Set %ax to $0x07C0
movw %ax,%ds // -> Data Segment
movw %ax,%es // -> Extra Segment
movw %ax,%ss // -> Stack Segment
ひとまずこの疑問はおいておいて、コードを先に読み進めていきます。すると、いきなりプロテクトモードへの片鱗が見え始めました。それは A20 ラインに伴う処理で seta20.1: というラベルからわかります。
アドレスバス A20 の処理
リアルモードからプロテクトモード移行にあたり、まず最初に必要になるのはアドレスバスを 32 ビット化することです。え?x86って32ビットバスではないの?という疑問をお持ちになる方がいるかもしれません。しかし、じつはここでも x86 は昔の?というかMS-DOS 時代の しがらみを引きづっているのです。
PC/AT アーキテクチャは電源投入後、アドレスバスの 21 本目にあたる A20 ビットは常にゼロになるような実によろしくないしかけが施してあるのです。なぜこんなめんどくさい仕掛けがあるのかを理解するためにはまず歴史を知る必要があります。
じつは MS-DOS時代のプログラム の中には、ラップアラウンドという事象を用いた技巧的なプログラミングテクニックが横行していました。 ラップアラウンドを利用したテクというのは、アドレス計算時のオーバーフローを逆手に取り、アドレス空間を一巡させてセグメントの先頭部分をアクセスするきわめてお行儀の悪いプログラムのことです。こんなお行儀の悪いコードでも、当時は大流行?しており、x86 に移行したがために従来のプログラム資産を使えなくなってしまうのは困ってしまう状態でした。そこでインテル開発者たちは互換性のために、A20 を制御することでラップアラウンドを保持しました。つまり、A20 ラインの制御はこの問題に対処するための苦肉の策だったというわけです。
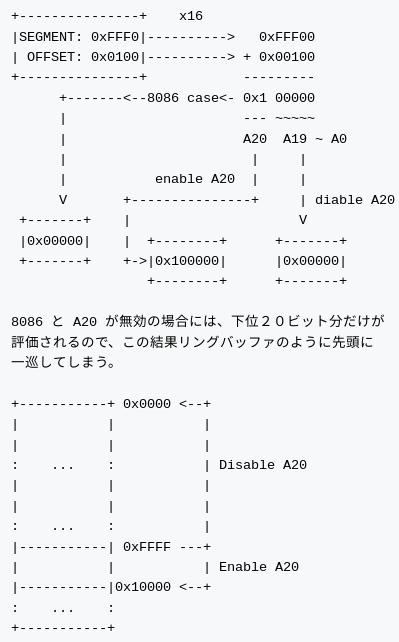
なお、A20 ラインの制御はキーボードコントローラ8042のポートの一部を用いて行われます。 以上の歴史的背景を元に A20 ラインを制御しているコードを具体的にみていきましょう。
seta20.1:
inb $0x64,%al // Wait for not busy
testb $0x2,%al
jnz seta20.1
movb $0xd1,%al // 0xd1 -> port 0x64
outb %al,$0x64
seta20.2:
inb $0x64,%al // Wait for not busy
testb $0x2,%al
jnz seta20.2
movb $0xdf,%al // 0xdf -> port 0x60
outb %al,$0x60
上記から2つのステージにわかれているのが見えます。正直ここのコード部分だけは個人的にいくつか納得できない部分があるのですが、あとで説明します。
こんな短いコードですが、この中身を正確に理解するためには、キーボードコントローラ 8042 の扱いに習熟している必要があります。具体的なキーボードコントローラの制御は PC/AT でも最も難解なものの一つです。ここではこのコード部分で登場する数字 0x64, 0x02, 0xD1, 0x60, 0xdf などの具体的な数値に注目して必要な部分だけをざっくりと解説します。
ここに記載以上の詳細に興味のある方は パソコンのレガシィI/O活用大全 などを参照してください。
キーボードコントローラ周辺回路
8042 は 128B RAM, 2KBのROM, さらに2つのポートを備えています。PC/AT互換機では8042のポート1を入力用、ポート2を出力専用として使用し、ポート2の方には CPU リセット端子(P20), A20ゲート端子(P21)、IRQ1(P24)、さらにマウス関連の端子などが接続されています。
IRQ1 はキーボードからデータを受信するたびに CPU へ割り込みをかけるためのものです。この仕組みにより x86 CPU はキーボードからのデータを割り込み処理により簡単に読み込むことが可能になります。A20ゲート端子とは、アドレスバスの 20 ビット目を制御するためのスイッチです。今回の題材ですね。プロテクトモードへ移行するときに利用されます。
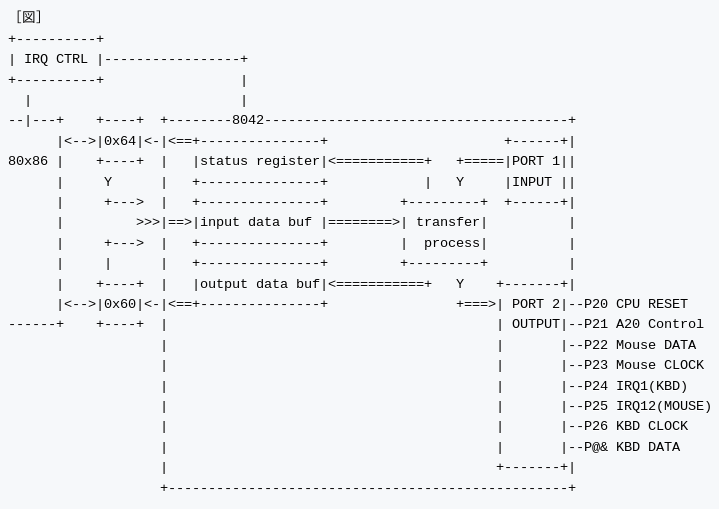
いったいなぜキーボードコントローラに CPU リセットや、32ビット化のための制御端子が接続されているのか謎ですが、これらの端子は80286 以降に搭載されたもので、当時他に接続ポートがあまっていなかったのでこのようになっています。
KBDコントローラ8042 制御
具体的な制御を理解するのは少し厄介な感じがします。操作対象は 8042 自身とキーボード、マウスと3つあります。これが混乱を招くポイントですが、3つの操作対象明確に区別して操作対象混同しないように注意していきましょう。さて、8042 はポート 0x64 を通じて「8042コマンドバイト」を送信することで制御します。
コマンドバイトには30近くの種類があるのですが、A20 ライン制御でもっとも重要なのは
0xD1: ポート2の設定
というコマンドバイトです。単純にポート 0x64 に 0xD1 を書き込むことでポート2を設定できるようになります。
なぜ 8042 のポート2を設定したいのでしょうか?これは上記の図を見ていただければ当たり前ですけど、A20ラインの制御が可能な A20 ゲート端子がポート2にあるからです。つまり、A20 を有効化する作業をするぞと合図を送るわけです。重要です。
データ入出力
0x64 の意味と 0xD1 の意味はわかりました。次に 0x60 の意味と 0xdf について見ていきましょう。
「8042コマンドバイト」は 0xD1 としてすでに送信済みです。次は、これに続く操作のために、「8042コマンドバイトのパラメータ」や、「デバイスコマンドバイトおよびそのパラメータ」、「キーボード・マウスからの受信データ、応答コード」を送信しなければなりません。そして、これらはすべてポート 0x60 を通してやりとりされます。操作対象の種類にかかわらず、データのやり取りが 0x60 ただ一つでおこなわれていることに注意してください。
重要なのはキーボードやマウスを制御するデバイスコマンドバイトが、この 0x60 ポートを利用するという点です。 0x64 に 0xd1 を書き込むと A20 を制御できるようになることは説明しました。つまり、具体的な制御はデバイスコマンドバイトを 0x60 に追加で書き込むことでおこなうのです。そして、A20 を有効化するデバイスコマンドバイトは 0xDF です。
つまり、 0x60 に 0xDF を書き込むことで A20 ラインは有効化されます。
なお、8042 は内部に「入力データバッファ」と「出力データバッファ」をもっていて、PC本体のCPUがデータを読み出す場合には後者を、データを書き込む場合には前者を利用すします(入出力の意味は 8042 から見た表現)。これに関連して、今バッファがどうなっているのかステータスを管理しなければならない厄介な点がありますが、このステータス管理はステータスレジスタを通して行います。A20ラインの制御についても例外はありません。
ということで、先に進む前にステータス・レジスタについても理解しておきます。ステータスレジスタの管理はポート 0x64 を読み込むことで行います。
8042 ステータスレジスタ
ポート 0x64 を読み出すとステータス・レジスタ(図:status register)の1バイト値を取得できますが、ここで重要なのは bit0, bit1 です。
8042 内部の入出力バッファは PC 本体のCPU側、および 8042 側の双方向からアクセス可能になっていて、データの保証がややこしいのですが、8042では双方向データ転送を実現するために、2種類の入出力フラグ(IBF/OBF)が用意されました。これがステータスレジスタの bit1/bit0 となります。
| ビット番号 | 意味 | ビット=1 | ビット=0 |
| bit1 | IBF | 入力バッファにデータあり | 入力バッファにデータなし |
| bit0 | OBF | 出力バッファにデータあり | 出力バッファにデータなし |
8042へ確実にデータを転送するために、内部的にも IBF/OBF を合図にしてデータ転送が行われており、プログラマもまた確実にデータ転送するために通常は以下の決まりごとを守っている必要があります。
ここでは書き込みしかおこなわないので前者に注意しておくだけで良いでしょう。なお、キーボードドライバを作成したことがあるかたはわかるかと思いますが、ここでの判定は A20 ラインの制御以外でもキーボードを操作していく上では重要です。覚えておいて損はないはずです。 A20 ラインの制御では応答コードは関係ないのでコマンドバイト書き込みの際の OBF については気にしなくても問題ないです。実際、xv6では気にしていないようです。
ここまでを踏まえて、たとえば、xv6の場合、処理の流れは以下のようになるのではないでしょうか。
- PC本体のCPUは、8042のIBFがゼロであることを確認し、データ0xD1をポート0x64に出力
- 0xD1が8042の入力バッファに読み込まれる
- IBFが一にセットされる
- 入力ポートフラグが1にセットされる(8042ステータス・レジスタのbit3)。このフラグから、8042はポート0x64を通じてコマンドバイトが書き込まれたことを知る
- 8042が入力バッファ中のコマンドを引き取る
- IBFが0にクリアされ、PC本体のCPUは8042へのデータ書き込みが可能になったことを知る
他にも便利な?コマンドバイトがたくさんあります。気になる方はググってみてください。
さて、ここまでやってやっと本題にはいれます。
A20をマスターしよう
ステージ1とステージ2に共通している操作からまず見ていきましょう。下記の部分です。
inb $0x64,%al // Wait for not busy
testb $0x2,%al
jnz seta20.1
僕だったらここは関数化してしまいたいところですが、関数として名前をつけるならflush8042関数でしょうか。その意味についてはいままでの解説をよんだ今ならわかるでしょう。
inb $0x64, %al でポート0x64を読み込んでいます。つまりステータス・レジスタの値を al レジスタ読みこんでいます。その次の testb $0x2,%al と jnz では、読み込んだ値と 0x2 との論理積をとることでビット1(IBF)が0であるか確認しています。0で無い場合には0になるまでループします。これは次に書き込みを行うための処置ですね。つまり、IBF がゼロになり 0x60 もしくは 0x64 ポートへの書き込みができるようになるまで待っているのです。
これを関数化して、Cで書くとしたらこんな感じでしょうか。アセンブリが得意ではない方はこちらをみて雰囲気をつかめるかと思います。
void flush8042(void) {
int stat;
loop:
stat = inb(0x64);
if (stat & 0x2)
goto loop;
}
一気に残りの処理も見てみましょう。もう簡単ですね。
seta20.1:
...
movb $0xd1,%al // 0xd1 -> port 0x64
outb %al,$0x64
この段階では、すでに IBF がゼロなので、 0x64 に 0xD1 を書き込めます。またこの操作によって、いまから 8042 のポート2を設定することを通知します
seta20.2:
...
movb $0xdf,%al // 0xdf -> port 0x60
outb %al,$0x60
この段階でもすでにIBFがゼロであることを確認済みなので、 0x60 にポート2のデバイスコマンドバイト 0xDF を書き込めます。書き込むとポート2がA20を有効化するように設定されます。
これで、アドレスバスは 32 ビット化されました。
なお、このコードはここで終わってしまっていますが、本来はA20ラインが本当に有効になっているのか、テストするコードを追加すべきなのでではないかと思います。本当は今後の発展のためにも追加して起きたかったのですが、これに触れていたら終わらなくなりそうなのでここでは省略します。xv6 に A20 ラインが有効か否かチェックするコードを追加するとしたら、どのようになるでしょうか。考えてみてください。もし実装された方がいたら、どのような実装にしたかおしえてもらえると面白そうですね。ぼくは実装してみました。
次にすすみましょう。
プロテクトモードへの移行
いよいよプロテクトモードに移行します!といってもコードとしてはたったの5行です。恐るるに足らずというやつですね。
lgdt gdtdesc
movl %cr0, %eax
orl $CR0_PE, %eax
movl %eax, %cr0
ljmp $(SEG_KCODE<<3), $start32
.
.
.
// Bootstrap GDT
.p2align 2 // force 4 byte alignment
gdt:
SEG_NULLASM // null seg
SEG_ASM(STA_X|STA_R, 0x0, 0xffffffff) // code seg
SEG_ASM(STA_W, 0x0, 0xffffffff) // data seg
gdtdesc:
.word (gdtdesc - gdt - 1) // sizeof(gdt) - 1
.long gdt // address gdt
ここでは、まず lgdt gdtdesc 命令により3つのセグメントディスクプリタからなる GDT テーブルをもつ gdtdesc ラベルのついたデータを読みこんでいますね。これの意味を説明するのは骨が折れますが一応説明しておきましょう。まず GDT について詳しくみておきます。
GDT is 何
GDTが何かを理解するためにはまず、プロテクトモードの大凡の仕組みを理解しておく必要があります。ここでは、リアルモードとの差異をふくめて概論的なものだけを一旦説明して、その後ソースを読みながら GDT の実態についても説明していきます。
【相違点とGDT概観】 リアルモードでは、セグメントは16bitで単にベースアドレスでした。セグメント値を4bit左シフトした値にオフセット(16bit)を足して20bit分のアクセスが可能なのでした。
例:0x1000:0x1000 = 0x11000
一方、プロテクトモードではセグメントレジスタには、単にGDT(Global Descpritor Table)というテーブル内のエントリ(ディスクプリタ)を選択するためのセレクタ値(オフセット値)を指定するだけです。ちなみに、GDT はある形式のデータの羅列で、メモリエリア内のどこにあっても構いません。 GDTのテーブルの各エントリ(ディスクプリタ)には、このセグメントについて、どのようにメモリを扱うべきかに関する設計書(ルール)が定義されています。ベースアドレスやlimit、属性などです。
例えば、ディスクプリタ(GDTのエントリ)では32bitのベースアドレスが定義可能ですが、これにオフセットを足すことで 32bit プロテクトモードでのリニアアドレスを算出できます。ベースアドレスというのは、リアルモードプログラムでセグメントレジスタに直接いれていたベースアドレスと似たようなものですが、セグメントに直接指定するのではなく、GDTとしてメモリ内に存在しているところが違います。 つまり、GDTのセレクタ値をセグメントレジスタに入れることで、そのセレクタに該当するディスクプリタがメモリ上から選択され、当該セグメントにおけるメモリの扱い方が、ディスクプリタ内に記載されている設計書のルールに従うことになります。 *なお、この GDT がないとプロテクトモードへは移行できません。
今、A20ラインは有効化されているのでアドレスバスはすでに 32 bit化されているのでした。正確に32bitを扱えるかどうかは、GDT の属性ビットの設定によるのですが、ベースアドレスはもともと32bit指定可能ですし、オフセットもlimitによりますが、32bitいけます。つまり、GDT の仕組みにより、保護モードでは 32bit のアドレス空間を触れることになります。
リアルモードに比べた保護モードの長所は以下のようになるでしょうか。
- Limit値は最大0xFFFFFFFFなので、ベースアドレス0を指定するとオフセット値だけで4Gバイト空間にアクセスできる!16bitリアルモードでは、64Kバイトの制約がありましたね。
- GDTテーブル内のDPLという値を制御して、コードセグメントとデータセグメントを分離したりして、システム層とユーザー層を区別して保護できる。
- ベースアドレスは物理アドレスで指定できる
コードベースで簡単に見ていきます。GDTは下記の部分で定義されています。
gdt:
SEG_NULLASM // null seg
SEG_ASM(STA_X|STA_R, 0x0, 0xffffffff) // code seg
SEG_ASM(STA_W, 0x0, 0xffffffff) // data seg
上記の定義はasm.h内で定義されている以下のマクロを使っています。ここはなんかわかりづらい気がしますね。
#define SEG_NULLASM \
.word 0, 0; \
.byte 0, 0, 0, 0
// The 0xC0 means the limit is in 4096-byte units
// and (for executable segments) 32-bit mode.
#define SEG_ASM(type,base,lim) \
.word (((lim) >> 12) & 0xffff), ((base) & 0xffff); \
.byte (((base) >> 16) & 0xff), (0x90 | (type)), \
(0xC0 | (((lim) >> 28) & 0xf)), (((base) >> 24) & 0xff)
#define STA_X 0x8 // Executable segment
#define STA_W 0x2 // Writeable (non-executable segments)
#define STA_R 0x2 // Readable (executable segments)
わかりやすくなるわけではありませんが、僕だったらここらへんのコードは C で書いちゃいたいなと思います。 例えば配列にすると以下のような感じですかね。
unsigned long long gdt[ 3 ] = { // GDT (3 ddescpritors)
0x0000000000000000, // 0x00 null descpritor
0x00CF9A000000FFFF, // 0x08 4GB-flat code (boot code segment)
// G = 4K, D = 32bit, P = S = 1,
// Type = exec/read, limit = 0xFFFFF
// Base = 0x00000000
0x00CF92000000FFFF, // 0x10 4GB-flat data (boot data segment)
// G = 4K, D = 32bit, P = S = 1,
// Type = read/write, limit = 0xFFFFF
// Base = 0x00000000
};
ここで書き直した方のコードを見てみると、x86のセグメントディスクプリタは8バイトから構成されていることがわかります。
今回は3種類用意されていますね。一つは NULL ディスクプリタ、残りの2つはブートプログラムのセグメント用です。また、実際にディスクプリタを要求するときには物理アドレスを使用するので、セレクタ値(セグメントを選択するためのインデックス番号のようなもの)も、これに則って1つめは 0x00, 8バイトあいて次0x08、さらに8バイト空いて次0x10 のようになっています。
コメントで簡単に説明を付加してますが、文章でも説明しておきます。 GDT の先頭部分、つまり1番目のディスクプリタは NULL ディスクプリタです。GDT では形式上最初に NULL ディスクプリタがないとけません。これは決まりごとの一つで、このNULLディスクプリタが存在しない場合にはエラーになってしまうので気をつけましょう。
2番目のディスクプリタ(0x08)はこのブートプログラムのコードセグメントです。コードセグメントについては、図で説明します。
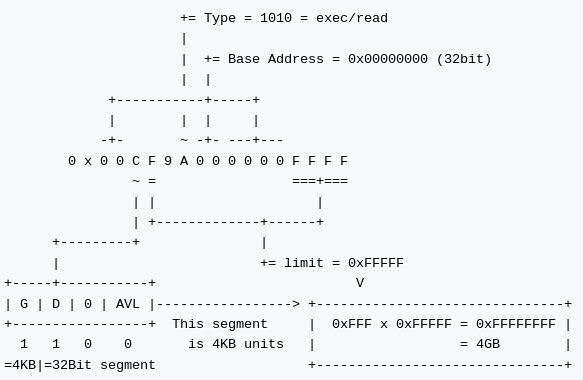
このセグメントのベースアドレスは 32bit で 0x00000000, limit 値も 32 bit で 0xFFFFFFFF = 4GB です。タイプの値から、実行と読み込みが設定されているのでコードセグメントであると判断できます。実行領域ですね。
3番目のディスクプリタ(0x10)はこのブートプログラムのデータセグメントです。このセグメントもベースアドレスは32bit 0x00000000, limit 値も32bit 0xFFFFFFFF = 4GB です。先程とタイプだけが異なり 0x2 = 読み込み/書き込みが設定されていることからデータセグメントであるとわかります。これを眺めてみると xv6 ではなぜリアルモードでセグメント0 のままだったのかわかる気がします【疑問4】。プロテクトモード移行後もセグメントのベースアドレスを0で揃えておくためだったようです。大きいコードは配置できませんが、このおかげでアドレス計算や最初に用意しなければならないGDTが少なく済み、コードが煩雑にはならない気がしています。xv6はこれを狙ったのではないでしょうか。
さて、こうして作った GDT はメモリ上に配置されているのでしたね。GDTを実際に扱うためにはセグメントレジスタにディスクプリタのセレクタを指定することでOKだったのですが、セレクタはあくまでもインデックスのようなものでGDTの先頭からのオフセット値にすぎません。このため、GDTの先頭を知らないことには CPU は GDT を扱うことができません。 ということで、なんとかして CPU に GDTのありかを登録してやらなければなりません。
この作業は CPU にある GDTR というレジスタに、GDTのサイズと、GDT の先頭アドレスを登録することで行います。これで、CPU は GDT にアドレスとセレクタ値をつかうことでアクセスできるようになるわけです。この操作は lgdt 命令でおこないます。下記です。
lgdt gdtdesc
...
.p2align 2 // force 4 byte alignment
gdt:
SEG_NULLASM // null seg
SEG_ASM(STA_X|STA_R, 0x0, 0xffffffff) // code seg
SEG_ASM(STA_W, 0x0, 0xffffffff) // data seg
gdtdesc:
.word (gdtdesc - gdt - 1) // sizeof(gdt) - 1
.long gdt // address gdt
とくに説明はいらないと思いますが、 lgdt で登録される 48Bのデータは gdtdesc: ラベルに定義されてます。実態は GDT のサイズと GDT の開始アドレスです。サイズの計算式は gdtdesc - gdt - 1 です。gdtdescは GDT の最後のアドレスの次を表しているので、1をさらに引き算しています。
以上で準備ができたので、いよいよプロテクトモードに移行しましょう。
いよいよ保護モードへ
コードは下記で、たった4行しかありません。
movl %cr0, %eax
orl $CR0_PE, %eax
movl %eax, %cr0
ljmp $(SEG_KCODE<<3), $start32
.code32 // Tell assembler to generate 32-bit code now.
start32:
現在の CR0 レジスタの内容を読み込み、最下位ビット(PE)ビットをオンにセットするだけです。なんともあっけないですが、本当にこれだけです。 たった、これだけの命令でリアルモードからプロテクトモードにほぼ移行しました。CR0 レジスタは CPU の機能を変えるためにプログラマが使用するレジスタですが、この最下位レジスタが保護モードへのスイッチになっていたのですね。
そのすぐ後で ljmp 命令を実行して、すぐ下の start32 アドレスにわざわざ jmp しているように見えます。これは一体になにをしているのでしょうか。
実はプロテクトモードに移行するときに、直後にジャンプ命令を実行することで命令パイプライン中をフラッシュすることができます。インテル CPU では、JMP命令かCALL命令を実行することで、CPUの命令実行パイプラインをフラッシュできる作法になっています。たとえば、リアルモードの命令語が残っている状態でプログラムが進行されると、次の命令語からは保護モードなのにもかかわらず、リアルモードの命令語を実行することになってしまい、プログラムの進行に支障をきたす可能性があるのです。 これでは困るので、Intel のお作法にのっとり、命令パイプラインを空にする必要があったのでした。
また、このJMP命令はその形態 ljmp $(SE_GKCODE<<3), $start32 からセグメント間ジャンプであることがわかります。なお SEG_KCODE=1 なので、コードセグメント用のセレクタ値(0x08)を選択していることがわかります。
展開すると下記のようになりますね。
ljmp $0x08, $start32
これは単に EIP を書き換えて制御位置を start32 アドレスに移動させるだけでなく、コードセグメントのロードも同時におこなっています(0x08の数値からわかるように、これはコードセグメントのセレクタ値)。
この一連の流れは初心者のぼくからしたら非常にスマートに感じました。GRUBではこのようなコードが利用されているのは知っていましたが、xv6も同じのようです。 【疑問】 初心者の僕からしたら、このコードは一石二鳥どころか一石三鳥ぐらいに見えて面白かったです。なぜ xv6 のこのコードがスマートに見えるのかは後ほど説明しまよう。
さて、ここで、はじめて完全にプロテクトモードに移行したと断言してもいいでしょう。 あとは消化試合ですね。
ljmp $(SEG_KCODE<<3), $start32
.code32 // Tell assembler to generate 32-bit code now.
start32:
// Set up the protected-mode data segment registers
movw $(SEG_KDATA<<3), %ax // Our data segment selector
movw %ax, %ds // -> DS: Data Segment
movw %ax, %es // -> ES: Extra Segment
movw %ax, %ss // -> SS: Stack Segment
movw $0, %ax // Zero segments not ready for use
movw %ax, %fs // -> FS
movw %ax, %gs // -> GS
// Set up the stack pointer and call into C.
movl $start, %esp
call bootmain
.code32 からわかるように、32bitモードつまり保護モード用のコードになります。残りのセグメントレジスタを設定してスタックも設定していますね。これで32bitモードでのプログラミングの下準備は完了しました。
あとは call bootmain により、いよいよ bootasm.S を飛び出してカーネルのロードへと処理が移っていきます。
【どこがスマートなのか?】 もしみなさんが自作ブートローダを作りたいと思った時に、これだけのコードではちょっと物足りなさもあります。ここでは少し寄り道して、この物足りなさを埋めつつ、僕が感じたスマートさもわかってもらうために追加で比較用に下記のようなコードを書いてみました。xv6 のものと対比させて、CPU の挙動について考えてみます。
// Move into protecot mode
movl %cr0, %eax // Get current CR0
orl $1, %eax // Turn on PE bit
movl %eax, %cr0 // Enter to protected mode
jmp flushing // Flush out the pipeline
flushing: // Now, we are in protected mode
movl $start32, %eax // Get offset address of start32()
movl %eax, (jmp_offset) // and save it to "jmp_offset"
movw $0x10, %ax // Our data segment selector
movw %ax, %ds // -> DS: Data Segment
movw %ax, %es // -> ES: Extra Segment
movw %ax, %ss // -> SS: Stack Segment
movw $0, %ax // Zero segments not ready for use
movw %ax, %fs // -> FS
movw %ax, %gs // -> GS
// CS setup (inter-sgmentjmp)
.byte 0x66
.byte 0xEA
jmp_offset: .long 0
.word 0x8
コード中には、一見して、意味のなさそうにみえる flushing ラベルへのjmp命令があります。これはもはや同じみの命令パイプラインのフラッシュですね。しかし、その後、コードセグメントを設定するまえに jmp_offset の位置に start32 のアドレスを格納し、データセグメントなどを設定してしまっています。ここまで読んだみなさんの頭の中には【疑問】が湧き上がるに違いありません。果たして、こんなことをしていいのか?と、プロテクトモード用のコードセグメントのセレクタ値をセグメントレジスタに設定できていないのに!?どうしてコードを実行できるのか?みたいな?
CPUがリアルモードからプロテクトモードへ移行した時、セグメントレジスタの内容は、リアルモードのときの値がそのまま引き継がれています。よって、flushing ラベルの直後の CS レジスタの値は 0 です。ここで、次のような疑問がデて来るのが当然です。
「CSレジスタはコードセグメントなのでセレクタ値 0x8 が設定されていないとおかしくないですか?」
そうです。プロテクトモードでは、GDTとそのセレクタによってアドレスを計算しているのでしたね。コードセグメントは実行するプログラムを読み込むための領域なのでプロテクトモードに移行した今、適切なセレクタ値が設定されていないとおかしい思います。
【答え】 ディスクプリは一度 CPU に読み込まれたら、CPU上にキャッシュされます。また、CPUはこの専用の領域にコピーされたこのディスクプリタ(コピー)を使いまわします。ということはですよ。まだ、CS には何も設定していませんので、このような時はどうなっているのかが鍵になるわけです。つまり、くどいようですが、CPUがプロテクトモードに移行した直後のセグメントレジスタを弄っていない状態ではどうなっているのかということです。
実はこの時、CPUが保持するディスクプリのキャッシュ領域には、リアルモードのようにアクセスできる初期値が設定されているのです。 また、この初期値のおかげで、CSレジスタのセレクタ値がまったく辻褄のあわないものになっていても問題なかったのでした。flushのあとも命令がなんなく実行できてしまっていたわけなのはこのためです。
さて、上のコードはこの初期値の仕組みに甘えて、先にCS以外のセグメント、つまりデータセグメントなどを一気に設定してしまっています。しかし、いつまでも初期値に甘えているわけにはいきません。最後にセグメント間ジャンプを実行して、start32へのジャンプとともにコードセグメントをロードしなければならないのです ということで、jmpするための似たような処理がこの先にあるに違いないと思って、先に進むと、どうも見慣れない命令群が出てきて再びつまづいてしまいます。jmpの記述がおかしいぞ、と。以下を見てください。
// CS setup (inter-sgmentjmp)
.byte 0x66
.byte 0xEA
jmp_offset: .long 0
.word 0x8
ここでは far jmp命令に相当する機械語をわざわざ手書きで入力しています。本当はxv6のコードのまま ljmp $(SEG_KCODE<<3), $start32 としても、この場合には構わないのですが、せっかく 32bit プロテクトモードに移行しているわけなので、その味を楽しもうとLinuxのブートセクタでのやり方を真似してみました。
なぜこんなことをしているのかちょっと考えてみます。
たとえば $start32 が16bitを超える値であったとしましょう( $0x100000 のような)。しかし、そうすると、残念なことに xv6 の下記のコードは、アセンブル時に、アセンブラからエラーを吐かれてしまいます。なぜなら、ここまでのコードは16bitのコードとして記述されているからです。jmp命令で16bitを超えるオペランドを扱うことができません。
エラー:「16-bit jump out of range」
.code16
...
ljmp $(SEG_KCODE<<3), $start32
実は、xv6では $start32 の値は大体$0x31程度と比較的小さいものとなります。従って、本来は16bitの範囲内に収まり問題ありません。支障なくアセンブルできます。ですが、ここはすでに、32bitのプロテクトモードの移行していますし、32ビット保護モードの領域へのジャンプするわけなので、jmp先も 32 bit である可能性もあると仮定しても何も問題ないのではないでしょうか。そのように考えてみると、面白そうです。なので、ここではジャンプ先も32bitであるとして、比較用にこのような書き方をして見ました。
また、これも奇妙で面白いことですが、実はGRUB2を見てみると最新のバージョンと少し前のバージョンで、このような部分の扱いがブレブレになっていることがわかります。つまり 16bit でOKか32bitとして扱うかについてです。気になる方は見てみてください。
さて、GRUB2 は一旦おいておいて、まず、なぜこのブロックだけ全て機械語で書いたのかについて、その理由を説明しておきましょう。といっても単純です。
これは単にアセンブラのエラーを回避するためだけにこのようにしたのです。まだ .code16 の中なので、16ビットコードの中で32bitオペランドを扱うことができないことはすでに説明しました。しかし、機械語を直接配置してしまえば、アセンブラから検知可能な不整合はなく、アセンブラがアセンブル時にエラーを吐いてくることはありません。
わざわざ機械語をベタ打ちした意味はたったこれだけの理由だったのです。
以上で機械語ベタ打ちの意味は明らかになりましたが、まだ羅列された機械語の意味は不明なままですね。 具体的な意味についても確認します。
0xEA はそのまま jmp 命令を機械語に置き換えたものです。CSには 0x8 が、オフセット(jmp_offset)には $start32 が入っています。そうすると先頭の 0x66 が異物のような感じがしますが、これは Intel x86 CPU に用意された prefix と呼ばれる魔法の呪文です。CPU に 16 bit 命令が32bitになったとか32ビット命令が16ビットに変わったということを CPU に知らせる目印です。
具体的には、 0x66 はoperand prefix というもので16ビットコードで 32bit オペランドを使えるようにするものです。16ビットモードでCPUが命令を実行中だけども、ここだけは 32bit オペランドをあつかってくださいと、 0x66 を付加することで CPU に指示しています。CPUがプロテクトモードに移行した直後では、CPUは初期値によって16bitモードで動くのでした。このため、この中で 32bit オペランドを処理してもらうために必要なのです。
なお、Linux のブートセクタではアセンブラのエラーを回避するために古くからこの方法が使われてきました。なお、ここでは、全部機械語で書きましたが、以下のような記述でも問題ないでしょう。
.code32
.byte 0x66
ljmp 0x8, $start32
ここでは、まず .code32 で32bitのコードであることをアセンブラに指示し、アセンブラのエラーを回避しています。しかし、CSはまだロードされていないので、初期値によってCPUはリアルモードとして使用できる状態です。ここで、0x66 の呪文を使用して、16bit モードでうごいていても直後の命令は 32bit オペランドを扱えるようにしているのです。
どちらの書き方がわかりやすいかはさておき、Gnu Assembler ではこの問題に対処するための術も用意されています。
Gnu Assembler(gas)ではこのオペランドプレフィックスを表すものとして、 data32 というプレフィックスが利用できます。そうするともっとわかりやすくなって単に以下のようになります。過去の GRUB2 ではこちらが利用されていました。
data32 ljmp 0x8, $start32
ここで解説した内容は、xv6 の場合には関係がありませんが、ご自身でブートローダーを作成するというときに役立つこともあるかもしれませんので覚えておいても損はないかとおもいます。 さて、横道にそれすぎましたが、ここまでの説明をよむと、如何に xv6 が徹底的に枝葉を切り落としてわかりやすいコードを書いてくれているのかがわかったような気になります。僕はドがつくほどの初心者なのでそのように感じただけかもしれませんが。
次にすすみましょう。 call bootmain でbootmainに処理が移るのでした。
カーネルをロードしよう!
bootmainシンボルは bootmain.cに定義されています。こちらもシンプルで短いので以下に抜粋しておきます。
#include "types.h"
#include "elf.h"
#include "x86.h"
#include "memlayout.h"
#define SECTSIZE 512
void readseg(uchar*, uint, uint);
void
bootmain(void)
{
struct elfhdr *elf;
struct proghdr *ph, *eph;
void (*entry)(void);
uchar* pa;
elf = (struct elfhdr*)0x10000; // scratch space
// Read 1st page off disk
readseg((uchar*)elf, 4096, 0);
// Is this an ELF executable?
if(elf->magic != ELF_MAGIC)
return; // let bootasm.S handle error
// Load each program segment (ignores ph flags).
ph = (struct proghdr*)((uchar*)elf + elf->phoff);
eph = ph + elf->phnum;
for(; ph < eph; ph++){
pa = (uchar*)ph->paddr;
readseg(pa, ph->filesz, ph->off);
if(ph->memsz > ph->filesz)
stosb(pa + ph->filesz, 0, ph->memsz - ph->filesz);
}
// Call the entry point from the ELF header.
// Does not return!
entry = (void(*)(void))(elf->entry);
entry();
}
void
waitdisk(void)
{
// Wait for disk ready.
while((inb(0x1F7) & 0xC0) != 0x40)
;
}
// Read a single sector at offset into dst.
void
readsect(void *dst, uint offset)
{
// Issue command.
waitdisk();
outb(0x1F2, 1); // count = 1
outb(0x1F3, offset);
outb(0x1F4, offset >> 8);
outb(0x1F5, offset >> 16);
outb(0x1F6, (offset >> 24) | 0xE0);
outb(0x1F7, 0x20); // cmd 0x20 - read sectors
// Read data.
waitdisk();
insl(0x1F0, dst, SECTSIZE/4);
}
// Read 'count' bytes at 'offset' from kernel into physical address 'pa'.
// Might copy more than asked.
void
readseg(uchar* pa, uint count, uint offset)
{
uchar* epa;
epa = pa + count;
// Round down to sector boundary.
pa -= offset % SECTSIZE;
// Translate from bytes to sectors; kernel starts at sector 1.
offset = (offset / SECTSIZE) + 1;
// If this is too slow, we could read lots of sectors at a time.
// We'd write more to memory than asked, but it doesn't matter --
// we load in increasing order.
for(; pa < epa; pa += SECTSIZE, offset++)
readsect(pa, offset);
}
このコードで本稿の解説は最後になりますが、個人的にこのコード部分は結構気に入っています。
まず、最初に ELF ヘッダ構造体ポインタ elf 、ELFのプログラムヘッダ構造体のポインタ ph, eph を宣言し、関数ポインタ entry とunsigned char型のポインタ pa が定義されていることがわかります。
struct elfhdr *elf;
struct proghdr *ph, *eph;
void (*entry)(void);
uchar* pa;
elf = (struct elfhdr*)0x10000; // scratch space
次に 0x10000番地をelfhdr構造体のポインタとしてキャストして、ポインタ変数 elf に格納することで、0x10000番地からの領域をelfhdr構造体として elf ポインタ変数を介してアクセスできるようにしていることがわかります。
// Read 1st page off disk
readseg((uchar*)elf, 4096, 0);
次はいきなり、readseg 関数によってディスクの先頭から4KBの領域を、メモリ上の elfhdr 構造体の位置(0x10000)に読み込んでいる様子が推測できます。elf 構造体は単純に unsiged char 型のポインタ変数にキャストされているので、データアクセスの際の最小単位が単純に1Bごとということでしょうか。このキャストのおかげでデータ構造の縛りはなくなっているので注意してください。第3引数はよくわからないですが、とりあえず今は、 elf ヘッダの大きさを無視して 4096B 読み込んでいるであろうことがわかれば十分です。
【疑問】 (なぜ 4096B なのかは疑問ですが...)。
以上より、readsegの実態はわからずとも、関数の引数の形態からどのようにデータアクセスをしているのかがある程度予想ができますね。C言語ではポインタとキャストが大事であるというのが実感できるのではないでしょうか。キャスト処理は適切にしておかないと大変なことになりそうです。 とりあえず、コードを読むために重要なことは、
ということを意識しておくことです。シンボルもldでアドレスを割り付けられるただのアドレスみたいなものですしね。結局、メモリイメージもデータで、データの実態は「アドレスとサイズ」の組み合わせなわけなのです。この考え方は、C言語では基本中の基本なので今一度心に刻み込んでおきましょう。
さて elfhdr や proghdr は elf.h に定義されていると思うので気になる方はそちらを参照してください。これを読んでるみなさんなら ELF の構造くらいは当然ご存知であるかと思うので、特に解説はしません。下記のサイトはおすすめです。僕はこれをよみながら elfdump もどきを自作したのでそれぐらいはしておくといいと思います。
http://refspecs.linuxbase.org/elf/gabi4+/contents.html
と、ドライにいきたいところでしたが Linux で生きていく上で現状 ELF はかなり大事な部類かと思いますので、少し寄り道して簡単に解説します。
概観 ELF
まず、プログラムとプロセスの違いについて簡単に触れておきます。 プログラムの実態は、実行コードやデータを格納した「実行可能ファイル」であると言えるでしょう。一方で、プロセスとは何かといわれれば、プロセスとは、変数のゼロクリアや参照シンボルのアドレス解決が終わり、いつでも実行可能もしくは実行中の状態にあるメモリ、あるいはCPUレジスタのことであると言えるのではないでしょうか。
こうしてみると、
「プログラムとはプロセスのメモリイメージをファイル中に焼き付けたもの」
とも言えますね。 そしてこの実行可能ファイルの形式の一つに ELF があります。
リンクと実行
ELF形式のファイルは下記図のような4種類のデータ構造から構成されています。
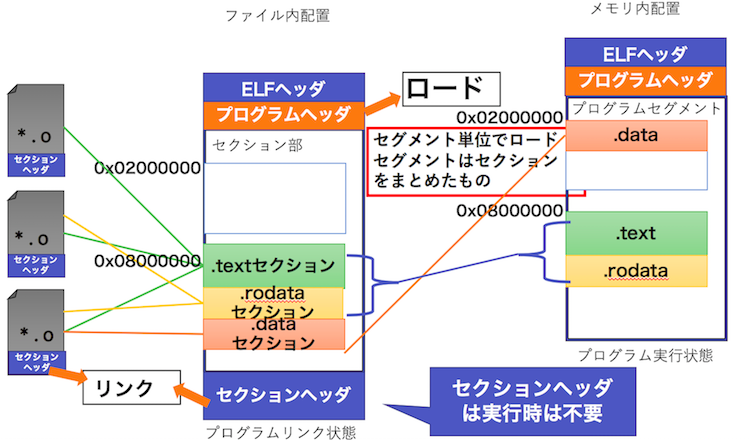
ELF形式の最大の特徴、つまり ELF を理解する上で重要なポイントは、プログラムの「リンク」と「実行」に応じて二重構造(二面性)が埋め込まれている点にあります。
まず、ELF形式の先頭には、ELFヘッダが付加されています。ELFヘッダは、ELF32/ELF64の区別やエンディアン、アーキテクチャなどの情報を持ちます。また、ELF 形式の内部は、複数のセグメントに区切られていて(プログラムヘッダーで管理されている)、さらにそのセグメントの内部が複数のセクションに区切られていること(セクションヘッダーで管理されている)がわかります。
これまでの言い方は厳密はには正しくないのですが、「リンク」に必要なデータ構造が「セクションヘッダ」であり、「実行」に必要なデータ構造が「プログラムヘッダ」です。具体的に見ていきます。
さて、コンパイラは、実行コードやデータだけでなく、数多くの付属情報を出力します。リンカーはこれらの情報をすべてオブジェクトファイル中に「セクション」という形式できれいに分類して格納します。このセクション群を管理するための構造がセクションヘッダです。セクションはセクションヘッダによって記述されます。ELF 形式の末尾には、セクションヘッダの配列としてセクションヘッダテーブルがあり、セクションヘッダエントリのそれぞれが、各セクションの情報を保持しています。
一方で、プログラムの実行時(プロセス生成時)には、これらのセクションはセグメントという領域として、種類ごとに一括してまとめられた上で、仮想メモリ上にロードされます。このセグメントを管理するための構造がプログラムヘッダです。プログラムヘッダは、セグメントのロード先アドレスや必要メモリサイズなどを保持しています。セグメントはプログラムヘッダによって記述されてます。ELF形式は、ELFヘッダの直後に、プログラムヘッダの配列としてプログラムヘッダテーブルを持っています。そして、それぞれのプログラムヘッダエントリが、各セグメントの情報を保持しています。
リンクと実行(ロード)は本来異なる作業です。いままで見てきたように、ELF 形式ではこのために、リンクの単位としてセクションを持ち、ロードの単位としてセグメントを持っているといえます。つまり、セクションはリンカのために存在するものであり、リンクはセクション単位で行われます。セグメントとロードに関しても同じことが言え、セグメントはローダのために存在するものであり、ロードはセグメント単位で行われます。
よって、ELF形式では、ロードが不可能なファイルは、プログラムヘッダを持ちません。このため、実行可能ファイルとダイナミックリンクライブラリはプログラムヘッダをもちますが、オブジェクトファイルはプログラムヘッダを持っていません。プログラムヘッダは、オブジェクトファイルのリンク時に、リンカによって付加されるものです。 つまり、プログラムリンク時には「プログラムヘッダー」がオプション扱いであり、逆にプログラム実行時には「セクションヘッダー」が不要になる点に注意してください。この特徴を活かして、セクションヘッダーはプログラムの最後尾に配置されているのです。このような構造にしておけば、プロセスイメージ生成時に単純に ELFヘッダーから最終セグメントまでをメモリ上にロードするだけでよくなります。
ELF を解析する
もう一度ソースを見てみると、いまだになぜ 4096 B なのかは謎ですが ELF ヘッダーをまず読みこんでいることがわかりますね。
// Read 1st page off disk
readseg((uchar*)elf, 4096, 0);
となると次は各種セグメントの読み込みでしょうか?次のコードを見てみましょう。
// Is this an ELF executable?
if(elf->magic != ELF_MAGIC)
return; // let bootasm.S handle error
おっと、まず ELF ヘッダの中身から何かしてますね。先にこれを片付けてしまいましょう。 このコードの意味を理解するためには、ELFヘッダのデータ構造を正確に把握している必要があります。下記のコードをみてみてください。下記は xv6 の elf.h とは関係ありませんが、このコードの意味を正確に理解しておくために僕が用意したものです。ELF ヘッダのデータ構造をCで定義してみました。まずは、これを使って ELF ヘッダの中身について復習しておきましょう(僕は、自分で作成した elfダンププログラムの中で僕は以下のコードを利用しています)。
//
// ELF header definition
//
union elf_header {
struct eh {
struct { // ID tag
uint8_t magic0, magic1, magic2, magic3; // ELF magic ID
uint8_t fclass, // File class
encoding, // Little or big endian?
version, // File version
abi, // os ABI
abi_ver, // os ABI version
padpos, // Start pos of padding
pads[ 6 ]; // Padding space
} id;
uint16_t type; // Object file type
uint16_t cpu; // CPU Architecture
uint32_t version; // Object file verion(ELF format version)
uint32_t entry; // Virtual address for the entry
uint32_t ph_offset; // Offset address of program header
uint32_t sh_offset; // Offset address of section header
uint32_t flags; // Processor-specific address
uint16_t eh_size; // This header size;
uint16_t ph_size; // Size of a program header(entry)
uint16_t ph_num; // Number of program header(s)
uint16_t sh_size; // Size of a section header(entry)
uint16_t sh_num; // Number of section header(s)
uint16_t sh_name; // Index of a sect header for name tbl.
} header;
char image[ sizeof(struct eh) ]; // Alias of elf_header.header{}.
} Elf;
ここで重要になるのは、コメント中のID tag の部分の id 構造体です(実際にはそのような構造体は存在しませんので注意してください。ここではデータ構造のわかりやすさを優先しています)。ELF形式のファイルの先頭には、かならずこの16バイトの領域が、バイト単位のデータとして存在しています。ここにはマジックナンバーや、ELF32/ELF64 の区別、ファイルのエンディアン、対象となるOSの種類の情報などが格納されています。
ここだけバイト単位になっている理由も大事です。エンディアンやELF32/ELF64 などの情報がわからないことには、ファイルの他の部分を読み込めないため、この先頭部分だけはエンディアンやビット数に依存することなく読み込める必要があり、そのためにここだけバイト単位でデータを羅列されています。 もう少しわかりやすく、表にしておきました。通常 ELF では、この16バイトの組は下記のような構成になっています。
| index | description |
| 0 | magic number |
| 1 | magic number |
| 2 | magic number |
| 3 | magic number |
| 4 | ELF32/ELF64 |
| 5 | endian |
| 6 | ELF format version |
| 7 | OS(ABI) |
| 8 | OS ABI version |
| 9 ~ 15 | padding |
xv6 の方の定義を見てみましょう。
// Format of an ELF executable file
#define ELF_MAGIC 0x464C457FU // "\x7FELF" in little endian
// File header
struct elfhdr {
uint magic; // must equal ELF_MAGIC
uchar elf[12];
.
.
.
思っていたのとはちょっと違いましたが、elfhdr の先頭に uint magic , uchar elf[12] と16バイト分の領域が確保されているのがわかります。先頭のマジックナンバーは 0x7f, 'E', 'L', 'F' であることがわかりますね。
さて、元のコードをもう一度確かめてみましょう。
// Is this an ELF executable?
if(elf->magic != ELF_MAGIC)
return; // let bootasm.S handle error
いまならこの意味がすんなりわかりますね。先頭4バイトがELFのマジックナンバーと一致しているかをしらべていたわけです。これが一致していることで、今からロードしようとしているプログラムが ELF 実行形式であることがわかります。
さて ELFヘッダを読み込んだわけですので、あとは、残りの最終セグメントまでをメモリ上にロードするだけでよくなります。セグメントはプログラムヘッダーで管理されているのでしたね。ということで、次のコードを見る前に、プログラムヘッダーをどのように扱うべきか、扱い方について見てみましょう。
プログラムヘッダーを扱うヒントも ELF ヘッダの中にあります。先程の構造体をみてみてください。以下の部分です。
...
uint32_t entry; // Virtual address for the entry
uint32_t ph_offset; // Offset address of program header
uint32_t sh_offset; // Offset address of section header
uint32_t flags; // Processor-specific address
uint16_t eh_size; // This header size;
uint16_t ph_size; // Size of a program header(entry)
uint16_t ph_num; // Number of program header(s)
...
ここでは、 ph_offset , ph_num が重要ですね。offset はプログラムヘッダーの位置のファイル中でのオフセット位置、 ph_num はプログラムヘッダーの数ですね。xv6ではこれらは、 phoff 、phnum として定義されています。プログラムヘッダーを扱い始める際に重要な情報で、これらの情報のおかげで、ファイル中からプログラムヘッダーの位置を読み取り、取得したプログラムヘッダーのデータから、セグメントをロードできます。
さて、プログラムヘッダの取り方はわかりましたが、肝心のプログラムヘッダーをどのように扱うべきかはわかっていません。扱い方は知るためには、どのようなデータ構造になっているかを知る必要があります。この際ですのでもう少し詳しく見ておきましょう。プログラムヘッダーは以下のような構造になっています。
//
// Program header definition
//
union program_header {
struct ph {
uint32_t type; // Segment types
uint32_t foffset; // Offset in the file
uint32_t vaddress; // Virtual address in memory
uint32_t paddress; // Physical addeess in memory
uint32_t fsize; // Size in file image
uint32_t msize; // Size in memory
uint32_t flags; // Flags
uint32_t align; // Address alignment
} header;
char image[ sizeof(struct ph) ]; // Alias of program_header.header{}.
} Program[ MaxPrograms ];
ここで、ロードするのに大事な情報は foffset , paddress , fsize , msiz の4つでしょうか。それぞれ xv6 の elf.h では off , pddr , filesz , memsz となっています。それぞれ、ファイル中での先頭からのオフセット位置、ロード先の物理アドレス、セグメントのファイル中でのサイズ、セグメントのロードされたメモリ中でのサイズを表しています。
memsz については、本来はfsize(filesz)と同じ値になるはずですが、BSS 領域など、ファイル中に実体がないセクションがセグメント中に含まれる場合には、msize(memsz)はfsize(filesz)よりも大きな値になることになるので注意してください。
vaddress(vaddr)は、セグメントのロード先の仮想アドレスで、通常はこのアドレスにロードして展開するのですが、カーネルのように実際に動作する論理アドレス(VMA )とロード先アドレス(LMA )が異なる場合には、その限りではありません。今回の場合はひとまずここ(vaddr)にはロードされず物理アドレスにロードされ、展開されます。このロード先の物理アドレスはリンカースクリプトの AT キーワードで指定されるのですが、それはまた後ほど。
以上より、off(foffset)とfilesz(fsize)より、セグメントのファイル中でのオフセット位置とサイズがわかるので、この情報よりセグメントのデータを読み込み、paddr(paddress)とmemsz(msize )より、ロード先の物理アドレスとメモリサイズがわかります。 のでここにロードすればいいことがわかります。実際にコードを見てみましょう。
カーネルイメージをロードしよう!
// Load each program segment (ignores ph flags).
ph = (struct proghdr*)((uchar*)elf + elf->phoff);
eph = ph + elf->phnum;
for(; ph < eph; ph++){
pa = (uchar*)ph->paddr;
readseg(pa, ph->filesz, ph->off);
if(ph->memsz > ph->filesz)
stosb(pa + ph->filesz, 0, ph->memsz - ph->filesz);
}
まず最初の行 ph = (struct proghdr*)((uchar*)elf + elf->phoff); をみると、読み込んだelfhdrの先頭アドレスにプログラムヘッダのオフセット位置を足すことで、プログラムヘッダーの先頭アドレスを取得していることがわかります。取得したアドレスは、proghdr 構造体のポインタにキャストして、 ph に格納することで、以後 ph を通してプログラムヘッダにアクセスできますね。まだ、なにもしていないので、プログラムヘッダーテーブルの先頭エントリを扱えます。
また、ここで、やっと、なぜELFヘッダ読み込み時に、 elfhdr きっかりのバイト数ではなく 4096B分を読み込んだのかがわかった気がします。ELFヘッダーは所詮 52 B しかないので、4096 B も読み込めば、プログラムヘッダーの先頭アドレスには確実にアクセスできますね。おそらく、ELFヘッダの直後に続くこのプログラムヘッダも一緒に扱いたかったために、4096B読み込んだのではないでしょうか。
次に eph = ph + elf->phnum とすることで、プログラムヘッダエントリーの最終アドレスを取得できることがわかります。 phnum はプログラムヘッダのエントリ数でしたね。 eph とはEnd of ProgramHeader あたりの意味でしょうか。
次のループがいよいよロードの最終段階です。
for(; ph < eph; ph++){
pa = (uchar*)ph->paddr;
readseg(pa, ph->filesz, ph->off);
if(ph->memsz > ph->filesz)
stosb(pa + ph->filesz, 0, ph->memsz - ph->filesz);
}
for(; ph < eph; ph++) から、最後のプログラムヘッダまでめぐるループをしています。具体的な中身を見ていきましょう。
pa = (uchar*)ph->paddr はプログラムヘッダからロード先物理アドレスを取得して、unsigned char 型のアドレスにキャストして pa に格納しています。 pa はphysical addressのことでしょう。
次に readseg 関数が再びでてきました。ここまで読んでくれば、この関数は read segment の略であろうことがよくわかります。また、readseg(pa, ph->filesz, ph->off); の各引数をみると先程まで謎だった第3引数の意味もわかってきますね。第1引数がロード先の物理アドレス、第2 引数がロードするセグメントのサイズ、第3引数がELFファイル中でのセグメントのバイトオフセットですね。 ということで、この readseg 関数によって、セグメントを物理アドレスにロードしている様子が推測できます。
readsegの実態は後ほど見るとして、ひとまず先にすすみましょう。
if(ph->memsz > ph->filesz)
stosb(pa + ph->filesz, 0, ph->memsz - ph->filesz);
お、これは!まさしく!という感じですね。memsz(msize)がfilesz(fsize)と一致しない場合で、memsz(msize)の方がfilesz(fsize )よりも大きいケースです。これは先程も言ったように、BSS 領域などで、ファイル中に実体がないセクションがセグメント中に含まれる場合に当てはまります。
stosb 関数がmemszの分だけ追加の領域を確保している様子が推測できますね。引数から推測できますが、おそらく0 で初期化しつつ領域を確保しているのではないでしょう。例えば、.bss 領域はゼロクリアされた領域ですが、実行時には前準備として何者かが必ずゼロクリアしておく必要があるのでした。
この推測が正しいのか、stosb関数を見てみましょう。stosb関数の実態は x86.hに定義されています。
static inline void
stosb(void *addr, int data, int cnt)
{
asm volatile("cld; rep stosb" :
"=D" (addr), "=c" (cnt) :
"0" (addr), "1" (cnt), "a" (data) :
"memory", "cc");
}
上をみると普通に stos 命令を使っており、推測が正しいことがわかりますね。stosb はデータサイズに関するオペランドプレフィックスがついている形式に似ていて、所定のレジスタを設定しておくことで、オペランドの指定を省略し、バイト単位でデータを転送することができます。ecx レジスタに繰り返しの回数(バイト数)が設定されています、stos命令の前に rep 命令が置かれているので、stos 命令が指定バイト数分を繰り返されることになります。今 data は0なので、0で埋められることになります。 stos命令については以下を参照してください。 https://c9x.me/x86/html/file_module_x86_id_306.html
本当は拡張アセンブラについても触れたかったのですが、時間がないのでここでは断念しました。気になる方は以下のリンクもご覧ください。 https://gcc.gnu.org/onlinedocs/gcc/Extended-Asm.html
このように、ファイル中に実態をもたないセクションを含むセグメントは、ロード時にmemszで要求されるサイズ分領域追加することで領域を確保します。
以上でロードの実態がつかめました。プログヘッダの数分だけループしているので、すべてのセグメントがそれぞれの対象の物理アドレス位置に、適正なサイズ分ロードされることがわかります。
ここでは readseg 関数を最後に確かめておこうと思ったのですが、時間的な制約により今回はここで諦めました。またどこかの機会で触れておきたいと思います。readseg関数の中身もハードとソフトの間の隔たりを取り去るという点で格好の材料なのではないかなと思います。
カーネルへ
最終行を解説する意味はあまりないかと思いますが、最後にみておきましょう。 この段階ではすでに、カーネルのイメージはELFのセグメント単位で所定の物理アドレスにロードされています。 あとはカーネルの実行に移っていくだけです。
// Call the entry point from the ELF header.
// Does not return!
entry = (void(*)(void))(elf->entry);
entry();
elf->entry は、ELFヘッダに格納されている ELF 実行形式のエントリアドレスです。このアドレスから ELF の実行がはじまる訳なので、xv6のカーネルイメージを実行するためには、ELFのエントリポイントに指定されたこのアドレスから実行を開始していけばいいわけです。いくつかのやり方が考えられる気もしますが、xv6 では単にELFのエントリポイントのアドレスを関数ポインタにキャストして、 entry シンボルを関数に見立てて関数呼び出しによって実行を開始しているようです。
【疑問】
でもちょっと待てよと思う方も多いのではないでしょうか。
今僕たちは論理アドレス=物理アドレスの世界でいきています。ELFヘッダのコメント内容から、ELFのエントリポイントは仮想アドレスではなかったでしょうか。大丈夫なのでしょうか。実行できますか? 今、ELF実行形式の各セグメントはすべて、物理アドレス上の位置に格納しており、ページングもOFFなので仮想アドレスは使えません。コメントはやはりエントリポイントは仮想アドレスであることを示唆しています
uint32_t entry; // Virtual address for the entry
つまり、この段階では物理アドレスから実行を開始する必要があるのに、ELFのエントリポイントは仮想アドレスが前提になっています。 どうやってこの問題に対処するべきでしょうか。xv6 での対応策を早速みてみましょう。
bootmain.c 中の entry シンボルの実態としての entry のアドレスをチェックしておきます。
entry 関数のアドレスの実態は entry.S の中に定義されてあります。
.text
...
// By convention, the _start symbol specifies the ELF entry point.
// Since we haven't set up virtual memory yet, our entry point is
// the physical address of 'entry'.
.globl _start
_start = V2P_WO(entry)
// Entering xv6 on boot processor, with paging off.
.globl entry
entry:
Turn on page size extension for 4Mbyte pages
Turn on page size extension for 4Mbyte pages
movl %cr4, %eax
orl $(CR4_PSE), %eax
movl %eax, %cr4
...
コメントが詳しくて勉強になりますね。最初の2行が大事です。
.globl _start
_start = V2P_WO(entry)
ELF実行形式のエントリポイントのデフォルトのシンボルは _start ですが、xv6はこの段階では、まだ仮想アドレスは使用できない段にあるので、呼び出しは物理アドレスでなければなりません。 xv6 では、どうやら V2P_WO マクロによって、entry.S中の entry シンボルの場所を仮想アドレス上の位置から、無理やり物理アドレス上の位置に変換して、ELF実行形式のデフォルトのエントリポイント _start 内部に格納しているようです。 そして、ここで設定された _start シンボルのアドレス位置が ELF 実行形式のエントリアドレスとなっています。
bootmain.c で使用した elf->entry の実態は ELF実行形式のエントリポイントなので、直接的な実態は _start シンボルのアドレス値です。
このため、entry.S 中の entry とは間接的には同じでも直接的には別ものですので注意してください。
また、これにより、セグメントは物理アドレス上に配置されているので、物理アドレスとしての ELF エントリポイントから実行を開始することで無事カーネルを実行できます。 最初にページングoffで仮想アドレスが機能しなくても、ELF を実行できるからくりはここにありました。
ちなみに V2P_WO マクロは memorylayout.h に定義されています。
リンカースクリプトを見ずとも、カーネルのメモリイメージ内部のメモリ配置の概観が目に浮かぶようです。
// Memory layout
#define EXTMEM 0x100000 // Start of extended memory
#define PHYSTOP 0xE000000 // Top physical memory
#define DEVSPACE 0xFE000000 // Other devices are at high addresses
// Key addresses for address space layout (see kmap in vm.c for layout)
#define KERNBASE 0x80000000 // First kernel virtual address
#define KERNLINK (KERNBASE+EXTMEM) // Address where kernel is linked
#define V2P(a) (((uint) (a)) - KERNBASE)
#define P2V(a) ((void *)(((char *) (a)) + KERNBASE))
#define V2P_WO(x) ((x) - KERNBASE) // same as V2P, but without casts
#define P2V_WO(x) ((x) + KERNBASE) // same as P2V, but without casts
上記の内容から、どうやら、ELF形式のエントリポイントの場所を仮想アドレスの場所(0x80000000以上)に設定するのではなく、無理矢理低メモリ領域である0x00000000の付近(ELFヘッダの読み込み位置を考慮するともう少し後方)に設定しているのではないかと予想ができます。
実行開始時の物理アドレスをもう少し正確に把握するためには、リンカースクリプトを見てみることが早いでしょう。 Makefile を見てみると、リンカースクリプトは kernel.ldです。
...
{
/* Link the kernel at this address: "." means the current address */
/* Must be equal to KERNLINK */
. = 0x80100000;
.text : AT(0x100000) {
*(.text .stub .text.* .gnu.linkonce.t.*)
}
...
0x80100000 とATキーワードが重要です。
V2P_WO の実態は仮想アドレスから 0x80000000を引くことで物理アドレスに変換するものでした。
ということは ELF エントリポイントの実態は物理アドレス 0x100000 よりちょっと後方あたりに位置していることになります。
この推測が正しいかどうかは AT キーワードを見れば一瞬でわかります。 ATキーワードはロードイメージ中のアドレス(ロードアドレス)を指定するためのものです。 ここではロードアドレスは物理アドレスですので、ロード先のアドレスは物理アドレス 0x100000 であることがわかり、やはり ELF のエントリポイントは 0x100000 あたりに位置していることが確かめられます。
readelf でカーネルイメージを確かめてみると実際のアドレスを真に知ることができます。
$ readelf -l kernel
Elf file type is EXEC (Executable file)
Entry point 0x10000c
There are 2 program headers, starting at offset 52
ELFのエントリポイントは 0x10000C でした!推測どおりですね。Cと落ち着かない数字になっているのは、Grubなどのmultiboot loader用のヘッダが entry.S 中の entry 以前に位置しているせいでしょう。
また、Makefile を見てみると、どうやら entry.S はカーネルイメージに入っていますね。これで皆さんはカーネルの入り口にたったことになります。
kernel: $(OBJS) entry.o entryother initcode kernel.ld
$(LD) $(LDFLAGS) -T kernel.ld -o kernel entry.o $(OBJS) -b binary initcode entryother
$(OBJDUMP) -S kernel > kernel.asm
$(OBJDUMP) -t kernel | sed '1,/SYMBOL TABLE/d; s/ .* / /; /^$$/d' > kernel.sym
まとめ
僕は、お仕事で Linux を触っていますが、わからないことだらけです。思うに OS Kernel の理解を阻む部分の半分はハードとソフトの間の溝に存在しているのではないかと感じます。しかし、ハードとソフトの間に横たわる溝を埋めつつ、その中に飛び込んでいくと、じつは思ってたほどには難しくないのではないかということに気がつくことができます。
まだまだ触り残した部分はありますが、今回の作業で、xv6カーネル島の周りに鬱蒼と茂っていた森は8割がたは消失したはずです(いいすぎかもですが)。 また、ここまでのブートアップの仕組みに関する内容から、xv6カーネルそれ自体も枝葉を切り落とされたシンプルで洗練されたかっこいいモノに違いないと予想ができます。最初の探検には最適だと思います。こちらも言い過ぎに過ぎる気もしますが本質は Linux も同じだとおもいます。
今回の内容から、Linux へ飛び込むもよし、ブートローダーをつくってみるもよし、OSを作ってみるもよしで、僕と同じ悩みを抱えている人にとっては、結構敷居はさがったのではないでしょうか?と期待します。
ところで、僕は x86 Linux 向けのブートローダーを作ってみました。 最後に僕の渾身の自作Linux ブートローダー動画を上げておきます。
までも行う意欲作のつもりです。 ブートローダーの自作、コマンドのビルド/デバイスファイルの配置、ルートファイルシステムの実装なども全部自力で行っています。 ちょっとしたオレオレディストリビューションといってもいいかなと思っています。こうやって遊んでいると、Linux への理解も深まります。
今回の内容をもとに探検をすすめればこのようなものを作るのさえ、決して難しいことではないのではと思います。ぼくのような凡百以下のエンジニア見習いでも、まったくの無知から、働きながら帰宅後の時間を使って約1ヶ月間をかけてつくったものです。みなさんもいかがでしょうか。 本来 Linux の深淵にふれるためには、ここ(ハードとソフトの溝を埋める作業)を避けて通ることはできないのではないでしょうか。
ソースは下記で!
https://github.com/ellbrid/bootloader
僕とおなじ悩みを持った誰かの役にたったなら幸いです。